Note: For
certain types of datasets, such as ASCII
and XML, you can define fields during
the initial dataset creation.
For other
datasets, such as Google harvest,
you can define fields once the initial dataset has been created.
Note: For
certain types of datasets, such as ASCII
and XML, you can define fields during
the initial dataset creation.
For other
datasets, such as Google harvest,
you can define fields once the initial dataset has been created. Fields are sections of dataset documents which have had their boundaries marked by delimiters, which have been defined (described) so that IN-SPIRE can recognize them. Delimiters can be almost anything that enables IN-SPIRE to find the chunk of text consistently. If no fields are defined, all the text in a document is lumped into a single field, which is then used by IN-SPIRE for clustering.
While defining fields is optional, if sections of your dataset's documents are labeled so they can be defined as fields, it will be possible for you to refine your analysis. Define fields when you want to do any of the following actions.
Cluster on a particular field rather than all the text.
Use the Time Slicer, which requires a date field.
Label documents in the Galaxy visualization and the Document Viewer using a Title field rather than with IN-SPIRE-assigned document numbers.
Query only a particular field.
What text always marks the beginning of each document?
What text always labels each of the parts of the document?
How can you tell where one part stops and the next begins?
Where is the "body" of the document? The body includes all text from the end of the last-defined field to the beginning of the next document delimiter.
It is not necessary to define a field for every labeled part of the document. If you do not define fields, IN-SPIRE will lump together the labeled parts. Depending on the structure of the data, this can introduce "noise," obscuring the analysis.
Note: For
certain types of datasets, such as ASCII
and XML, you can define fields during
the initial dataset creation.
For other
datasets, such as Google harvest,
you can define fields once the initial dataset has been created.
To define fields in your dataset, begin with a dataset, either when you are creating a new dataset, or by editing an existing dataset.
From the IN-SPIRE File menu select Datasets. The Dataset Editor will display.
From the Dataset Editor window, select a dataset from the list and click the Edit button. The Dataset Wizard will display.
Click Next> to navigate through the steps until
you reach the Format Fields step. For
the example shown, a Google Harvest
dataset is being edited and Format Fields displays on Step 5 of the Dataset
Wizard. The
step number can be different depending upon what sort of dataset you are
creating or editing.
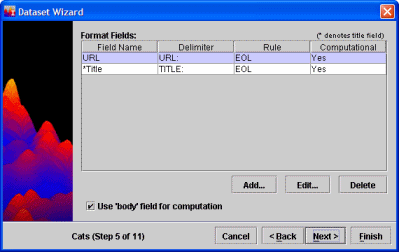
From the Format Fields step, select a Field Name
from the list and click the Add button. The Field Properties window will
display.
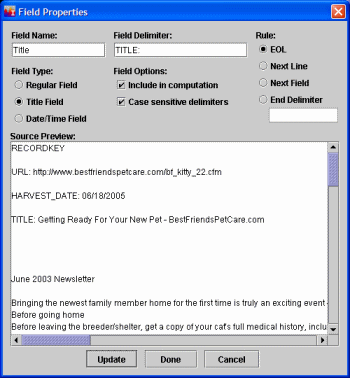
From the Field Properties window, edit the field.
You can
use the Source Preview pane at the bottom of the Field Properties window
to look at the dataset documents while you create a field.

Choose a descriptive name for the Field Name. When a document is displayed in the Document Viewer, this field will be labeled with the field name.
Enter the Field Delimiter text which will always mark out this field in the dataset documents. In the above example, the Field Delimiter is TITLE :. Enter it exactly as it appears (spaces and punctuation are important, in this example, the colon is included after the word 'title').
To ensure that the Field Delimiter you enter is exactly what is found in your documents, copy field text from the Source Preview window. To quickly copy text in the Source Preview to Field Name, Field Delimiter, or End Delimiter fields, in the Source Preview area, highlight the text you want to use.
Right-click on the selected text. A
drop-down menu will display.
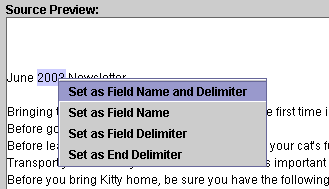
From the drop-down menu, select the fields to which you want to copy the text.
If you have not already selected a delimiter
Rule for your field, select one from the list.
Select a Field Type. Most fields will be Regular Fields.
Select Title Field to label documents in the Galaxy, rather than using the IN-SPIRE-assigned document numbers. Titles can be visible in the Galaxy and in some other tools such as the Document Viewer as well.
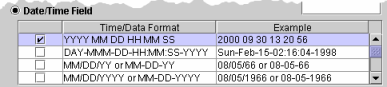
Select Date/Time
Field to use this field for the Time Slicer. Select
a Time/Date Format from the box that will display.
Select Field Options.
Select Include in Computation to have IN-SPIRE use the terms in this field when calculating the statistics that determine topical content and organize your documents into clusters. Usually you will want to use all of your non-date fields for computation, unless a particular field contains irrelevant data or data that is of little interest for the analysis. If the field is not used for computation, the terms in that field will be ignored when calculating the topical characteristics of your documents, but the terms will be available for queries and gisting.
Select Case Sensitive Delimiters to distinguish this field delimiter from others with the same spelling but different capitalization.
To tell when one field ends and the next begins, use the following guidelines when selecting the delimiter Rule.
|
If the field ends here: |
Choose this: |
|
At the end of the line. |
EOL |
|
At the next line. |
Next Line |
|
At the beginning of the next found field.
|
Next Field |
|
Marked by a delimiter
If the end delimiter is not found, then the field is not found.
|
End Delimiter |
7/18/05