Datasets: Blog Harvest
Follow steps 1-3 of the Basic Steps for creating a new dataset. Then you will see:
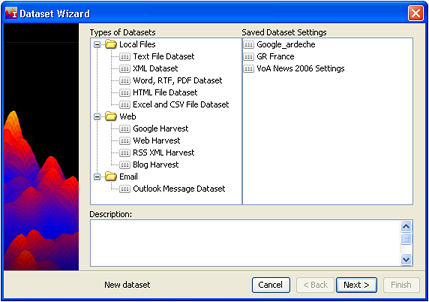
- Click Web > Blog Harvest, then click Next >.
- The following screen displays:
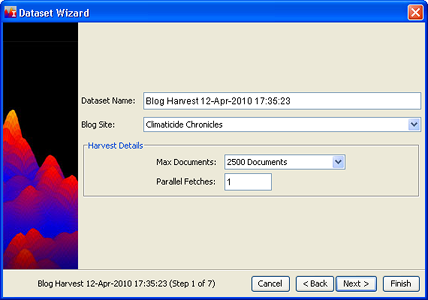
Enter a Dataset Name, or accept the default name, which is "Blog Harvest <date>".
- At the present time, Climaticide Chronicles is the blog which can be harvested. A blog harvest is akin to a Web Harvest in that all pages from the blog site will be harvested up to the specified total number of documents. By contrast, Google Harvests search for documents containing particular words.
- Set Max Documents, the total number of documents that the harvester will return. Usually the dataset will contain somewhat fewer than this number because not all document "fetches" will result in a usable document. The default number is 2500, but you can harvest as many as 20,000 documents from a single site.
- Set Parallel Fetches. The default number is 1, but faster processors or computers with multiple processors can handle several harvester threads simultaneously. If several harvester threads are active simultaneously, the harvest can potentially be completed in less time than it would be were there only one harvester thread. If in doubt, set the number of parallel fetches to 1.
- Click Next and go to Optional Settings or to start processing using the default settings, continue to the next step.
- Click Finish to start processing. The Processing dialog opens, informing you that the dataset is being processed. Click OK. The dataset name appears in the list of datasets in the Dataset Editor window. You can monitor its status as it is processed by clicking the Refresh
 button at the top of the Dataset Editor window.
button at the top of the Dataset Editor window.