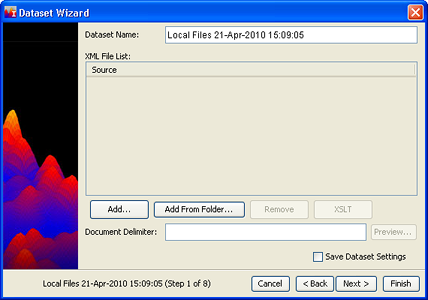
Follow steps 1 and 2 of the Basic Steps listed in Creating a New Dataset, and select XML Dataset. The Dataset Wizard XML window displays.
Enter a Dataset Name.
Enter the Document Delimiter. The delimiter is the content of the XML tag, without angle brackets or a slash; it will typically be a word or words enclosed in angle brackets, and will be within the first three lines of your XML file(s). A corresponding XML tag with a "/" in front of the word will be near or at the end of the XML record. For example, <DOC> occurs at the beginning of the XML file, and </DOC> occurs near the end. The IN-SPIRE document delimiter would be DOC in this case.
Click Add ... to add XML files (singly or severally), or click Add From Folder... to add an entire folder full of files. Browse to the folder you want to add, click on it to select it and click Add. The files appear in the Source files list. To remove a file from the Source files list, click on it, then click Remove.
Associate source files with XSLT files. XSLT files are used to transform XML tagged data into some other format for viewing. To associate XSLT files
Click on one or more source files that you want to associate an XSLT file with. Ctrl-A will select all source files in the list.
Click on the XSLT button. A file open dialog opens in the IN-SPIRE sources folder.
Navigate to your XSLT file, if it is not in the sources folder.
Click Set. The XSLT file name appears next to the source file with which you have associated it.
Click Next. The Format Fields window will appear. See Defining Fields for general guidance on how to define fields. Note especially that a field delimiter should not include the angle brackets of the XML tag. For example, for the field <DOCUMENT_ID>, DOCUMENT_ID is the field delimiter.
 Make sure at least one of the XML fields that are marked "Computational" actually exists in most of your documents, and that it contains significant textual content. If it does not, the IN-SPIRE text engine will not find enough data to create a visualization and will fail.
Make sure at least one of the XML fields that are marked "Computational" actually exists in most of your documents, and that it contains significant textual content. If it does not, the IN-SPIRE text engine will not find enough data to create a visualization and will fail.
Having IN-SPIRE automatically group the contents of a field by value can be useful, if the field contains a limited number of values, for example, regions, countries, or areas, that can be useful to the analysis. Check the Group by Field alue checkbox to choose this option.
To accept the default settings on the following screens and begin processing immediately, click Finish and go to the next step, otherwise go to Optional Settings.
 button at the top of the Dataset Editor window.
button at the top of the Dataset Editor window.DTD files are not currently supported. If your XML files reference DTD's, although the XML files will be processed, the DTD references and DTD files will be ignored during processing.
 Your XML source files must be well-formed. For the rules which define proper XML structure, see any XML reference book.
Your XML source files must be well-formed. For the rules which define proper XML structure, see any XML reference book.