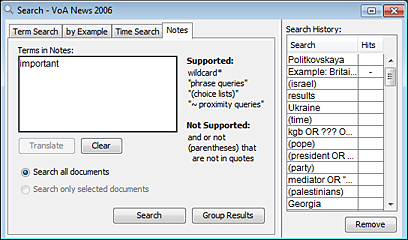
There are four types of searches: Term Search, by Example, Time Search, and Notes. For a description of these searches and some guidelines for when you might want to use each of them, see Search: Basics.
You can search from other IN-SPIRE locations, including the Document Viewer and the Summary panel in the left sidebar. In all cases:
 search button to open the Search Tool.
search button to open the Search Tool.Search terms can be cut and copied from a Word or text document and pasted into the Quick Search box or search text field in the Search Tool.
Datasets created in IN-SPIRE 5.0 and beyond will use the following search syntax:
Single Words. Match the specified word and may include the wildcard characters ? and *.
Phrases. Match a specified sequence of one or more elements defined within double quotes "…"
Ordered Phrases. Match an ordered sequence of elements defined within brackets [ ] and optionally a leading asterisk * followed by a number indicating the potential distance between elements in the phrase.
Unordered Phrases. Match an unordered sequence of elements defined within brackets [ ] which has a leading tilde ~ and optionally followed by a number indicating the potential distance between elements in the phrase.
Choices. Match one or more of the elements defined within parentheses (…).
AND, OR, NOT. Each Boolean operator is applied to the two elements that surround it in the search.
For more details and examples on term search syntax, see Search: New Term Search Capabilities.
Datasets created before IN-SPIRE 5.0 will use the following search syntax:
Phrases. Enclose a search phrase in quotes. For example, "islamic". Within the phrase you may use an asterisk (*) as a wildcard.
Multiple Words. Connect words in the Search Text box with AND, OR, or AND NOT, to construct a Boolean search (! is ignored, as are XOR, and |).
Wildcards. You can use an asterisk in a term search as a "wildcard" representing characters or words.
Since IN-SPIRE substitutes a space for any punctuation, contractions such as "don't" become two words, "don" and "t". Use wildcards such as *2 to find contractions that were split during processing.
Wildcards. Use an asterisk at the end of a word for word stemming. For example, "defen*" will return documents containing any words beginning with "defen", including "defense", "defend", "defensive", etc.
The default is to search All Fields, but it is sometimes helpful to search only one or two fields, for example, if searching All Fields returns many analytically-unhelpful documents, or if the dataset has a field which you can use to restrict the search in a useful way.
If you choose to search more than one field, it is important to note that the entire search is run against each of the specified fields separately. Such a search returns documents for which one or more of the selected fields satisfies the search criteria. The search is not applied acrossthe specified fields. For example, suppose you selected the TITLE and AUTHOR fields, and then entered the following search text:
Abbott and Costello
This would return documents with both words, Abbott and Costello, in the title, or both words in the author field, or both words in both fields. Note that this search would not return a document with the following field content:
TITLE: The Life and Times of Bud Abbott
AUTHOR: I. B. Costello
This is because neither the content of neither field taken by itself satisfies the search criteria.
 One effect of this rule is that selecting all of the individual fields in the Fields list is not equivalent to selecting All Fields.
One effect of this rule is that selecting all of the individual fields in the Fields list is not equivalent to selecting All Fields.
The Document Viewer displays the relevance of documents retrieved by a term search, analogous to the quality of the match shown for Search by Example results. Relevance is computed from:
Independence: The relevance of each document returned by a search is independent of any other document returned by that search.
Coverage: The more search terms found in a document, the higher its relevance.
Balance: An even distribution of search terms found in a document outranks an uneven distribution.
Complexity: The more complex the search, the less coverage required for a document to achieve a given relevance score.
Size: Shorter documents will have higher relevance scores, all other things being equal.
Punctuation rules, which are created when a dataset is created, apply not only to the search expression but to the content of any document to be searched.
For example, suppose you want to "de-hyphenate" all hyphenated words, such that "hold-up" maps to "holdup." To do this:
In the reprocessed dataset, a document that contains both "holdup" and "hold-up" will respond exactly the same to a search for the word holdup, the word hold-up, the phrase "holdup" "hold-up."
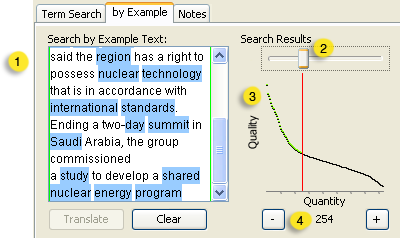
Search by Example lets you find documents similar to a an example you supply, for example, a complete document or part of one. To create a Search By Example:
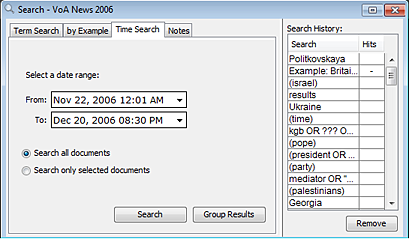
Time Search enables you to search for documents by selecting a date range within a dataset. To run a Time Search:
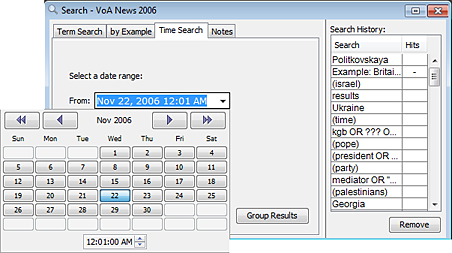
Searching Notes enables you to find words and phrases in notes attached to documents. These are notes you or colleagues have created. If a dataset has not been annotated, a search on the notes will yield no results. To search Notes: