Data Sets
Overview
Creating New
--ASCII Text
--XML
--Google Harvest
--Web Harvest
Settings
--Fields
--Stopwords
--Stopmajors
--Punctuation Rules
Editing
Merging
Exporting
Importing
Subsetting
Visualizations
Galaxy
--Basics
--Outliers
ThemeView
Settings
Tools
Document Viewer
Gist
Groups
--Basics
--Evidence Panel
Major Terms
Queries
Print
Probe
Time Slicer
About version 2.2
Overview
Known issues
![]()
Settings: Punctuation Rules
By default, IN-SPIRE ignores all punctuation. Word boundaries are defined by white space. All punctuation--periods, quotes, commas, etc.--becomes white space or is deleted. For some analyses, however, this default behavior does not produce the desired result, Data containing e-mail addresses or web pages, for example, present a challenge, because using its default punctuation rules, IN-SPIRE will parse "someone@somewhere.com" as "someone", "somewhere" and "com"; probably not what you'd prefer.
Fortunately, IN-SPIRE allows you to customize how it processes punctuation characters. You can create a Punctuation Rules file for a particular data set, or save it for use in subsequent analyses.
![]() Because
application of the punctuation rules is the first step in processing a
data set, keeping a character or deleting a character can have sweeping
effects.
Because
application of the punctuation rules is the first step in processing a
data set, keeping a character or deleting a character can have sweeping
effects.
Accessing the Punctuation Rules for a data set
The Punctuation Rules are accessible from the Data Set Editor's Data Set Wizard, which will be open when you create a new data set. If it is not:
- Choose File > Data Sets. . . The Data Set Editor window opens.
- Click on the name of the data set of interest to select it, and click
Edit, or click New. The Data Set Wizard opens.
 If a data set is open, you will be given the option to close it and
continue, or cancel.
If a data set is open, you will be given the option to close it and
continue, or cancel. - If you are editing an existing data set, click Next until
you see the Punctuation Rules panel (for an ASCII data set, this is
Step 5of 6). If this is a new data set, you must select a data set name
and data type to go on to the Punctuation Rules panel.
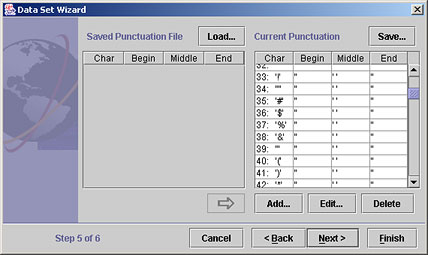
If the Data Set Wizard is already open, use the <Back and Next> buttons to find the Punctuation Rules panel, which is Step 5 of 6.
Editing the Punctuation Rules for a data set
Each line in the panel at the right contains a punctuation "rule" for one character. It lists how that character will be treated by the text engine, as it reads source documents and creates a data set. The columns Begin, Middle and End, show what the text engine will replace the character with, if it occurs at the beginning, middle, or end of a word.
- To change the rule for a character, click on the character in the
list to select it and click Edit. The Edit Rule window opens.
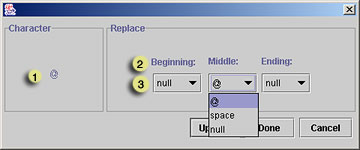

When this character appears at the. . . 
Beginning, Middle, or End of a word. . . 
replace it with the selected character.
To preserve the "@" character in e-mail addresses, enter an "@" in the Middle: box, so that any "@" that occurs in the middle of a word will be preserved, resulting in joe@somewhere being considered all one word. - To save your change and close the Edit Rule window, click Done.
- To save your change without closing the Edit Rule window, click Update.
The Current Punctuation list reflects the change and the Edit rule window
becomes:
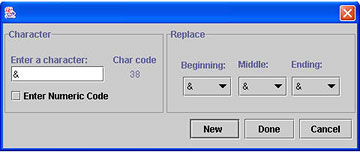
- Now you may add or modify rules by
- Entering the character, following steps 1-3 above; or
- Entering the ASCII code for the character.
- If you check the Enter Numeric Code, the window changes to:

Follow steps 1-3 above. - To add/modify another rule, click New. Otherwise click Done. The Edit Rules window closes and changes are reflected in the Current Punctuation list.
Adding punctuation rules from an existing punctuation rules file to the Current Punctuation list
- Click Load. A file open dialog opens to the IN-SPIRE punctuation rules directory.
- Choose the punctuation rules file in the list that you want to open,
and click Load. The file open dialog closes, and the chosen
punctuation list is loaded into the list on the left of the Punctuation
Rules panel. The name of the file is shown immediately above it.
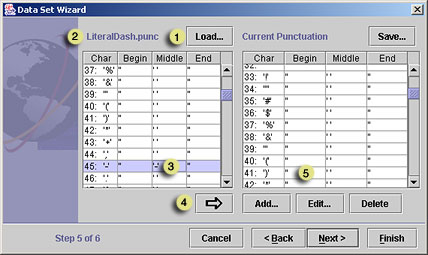
- Select the punctuation rules you want to add:
To add a single punctuation rule from the file to your Current Punctuation list:
Click on the word in the list to select it.
To add several rules in the list, select them using CTRL-click for non-contiguous rows, SHIFT-click for contiguous rows.
To add all punctuation rules in the file to your Current Punctuation list:
Click in the list box on the left.
Click CTRL-A to select all punctuation rules in that list.
- Click
 to add the selected rows to the Current Punctuation list.
to add the selected rows to the Current Punctuation list. - The selected terms appear in the Current Punctuation list.
You may use punctuation rules from another file as well, click Load again and repeat the above steps.
To save the Current Punctuation list for use by other data sets
- On the upper right of the Punctuation Rules panel, click Save... A file save dialog opens.
- Enter a name for this punctuation rules file.
 The
name of a punctuation rules file must end in ".punc"
The
name of a punctuation rules file must end in ".punc" - Click Save.
Editing the default punctuation rules file
All new data sets use the default punctuation rules file. You may use the Punctuation Rules panel to modify this default punctuation rules file.
- Load the default punctuation rules file that is distributed with IN-SPIRE (00000000.punc) into the Punctuation Rules panel, as above.
- Add all or some of the rules in the file to the Current Punctuation list.
- Add and delete rules as appropriate.
- Save the Current Punctuation list as "00000000.punc" to
the INSPIRE\DatasetRoot\ folder .
Be
careful of the number of zeroes in the filename; there should be eight
of them.